

摘要
常用的识别方法是将软件系统抽象为一个类依赖网络,再根据定义好的度量指标和计算规则计算每个节点的重要性得分,如此基于非训练框架得到的关键类,并没有充分利用软件网络的结构信息。
基于图神经网络技术提出了一种有监督的关键类识别方法。
0引言
GKCI:
GNNs 旨在利用图结构和节点或边的属性信息来学习节点或图的表示,并用于下游任务中。 然而, 现有的 GNNs 大多是基于向量的嵌入聚合,而学习出来的节点特征向量实际上不能直观地表示节点的重要性。
本文通过改进 GNN 模型, 提出一种新的关键类识别方法(GNN-based key class identify, GKCI). 其过程大致如下:
- 首先,利用网络嵌入学习提取类依赖网络中每个类节点的表征向量;
- 接着,采用一个网络映射将节点的表征向量转换为一个标量, 作为节点的初始分值;
- 然后,对目标节点的邻居分值进行聚合,考虑不同邻居对目标节点的影响不同,在聚合时,将方向和权重也纳入计算;
- 最后,根据节点的得分进行降序排序,从而实现关键类的识别。
GKCI 方法的步骤 :
- 给每个同学「画像」
- 网络嵌入学习 :先用一种特殊算法(Node2Vec)分析同学关系网,给每个同学生成一个数字「画像」(表征向量),这个画像能反映他在朋友圈中的位置(比如是不是总爱当组织者、有没有跨班级的朋友等)。
- 把画像转成初步评分
- 映射成分数 :用一个简单的数学公式(全连接层),把每个同学的「画像」压缩成一个数字(初始分值)。这个分数可以理解为:根据他的朋友圈结构,他可能有多大的影响力。
- 听取朋友的意见
- 聚合邻居的分值 :接下来,算法会考虑每个同学的朋友对他的影响:
- 方向 :比如A是B的班长,A对B的影响可能比B对A的大(单向箭头)。
- 权重 :如果A和B经常一起合作(比如每周一起办活动),他们的连线权重就高,A对B的影响会更大。
- 调整分数 :综合所有朋友的影响力(方向+权重),重新计算这个同学的最终得分。
- 聚合邻居的分值 :接下来,算法会考虑每个同学的朋友对他的影响:
- 排名揭晓关键人物
- 把所有同学按最终得分从高到低排序,得分高的就是「关键人物」——这些人的离开可能会让整个学校运转困难。
GKCI 的改进 :
- 用AI学规律 :不是靠固定规则,而是用神经网络从数据中自己学规律。
- 考虑方向和权重
- 动态调整 :每个同学的影响力不仅看自己,还看他的朋友有多厉害(比如朋友如果本身是关键人物,那他对你的影响也更大)。
与GNN相比优点;
- 改进了 GNN 模型的邻域聚合函数。即,通过聚合目标节点邻居的分值来代替以往的向量聚合,提出了一种可更直接捕获节点及其邻居重要性的有监督的深度学习方法,以提升软件系统中关键类的识别效果;
- 探析了软件系统中类依赖关系的方向和权重信息的影响,并在 8 个开源软件上进行了实证分析, 发现权重比方向在关键类识别上更具有参考价值, 且本文所提 GKCI 方法在有向加权情境下, 识别效果比基准方法(DC[8]、BC[8,9]、H-index[10]、K-shell[11]、PageRank[12,13]、文献[23]和文献[24])具有更显著的提升.
1 相关工作
发展与产生
- 深度学习的不断发展,图数据得以使用深度学习范式进行学习,为网络中节点重要性排序提供了又一种新思路。
- Fan等人设计了一个基于编码器-解码器的图神经网络框架,利用编码器将网络结构中的每个节点表示为一个嵌入向量,再通过解码器将向量转换为标量,并以节点的介数中心性 BC 值作为重要性标准进行学习训练,弥补了 BC 指标在大型网络上计算耗时的不足,但该方法准确率的上限是 BC。
- 张健雄等人提出一种改进方法,采用节点收缩法衡量节点的排序结果。没有考虑软件网络中边的方向,并且邻域聚合过程对节点的嵌入向量进行聚合。
- Park 等人提出一种解决知识图谱领域中节点重要性评估问题的方法 GENI, 该方法基于 GAT 而加以改进, 将节点的初始信息转换为重要性分数, 并使用灵活的中心性调整来聚合重要性分数, 而不是聚合节点嵌入. 得益于监督学习框架和图神经网络, GENI 实现了比无监督算法更高的性能.
对于软件关键类识别研究, 主要难点有:
- 目前大多数关键类识别方法都是基于非训练的框架,鲜有研究使用深度学习框架自动学习软件网络的信息;
- 软件网络建模过程中,往往只单一地考虑边的方向或权重信息;
- 现有的图神经网络模型在邻域聚合过程中都是对节点的嵌入向量进行聚合,难以直接反映邻居节点的差异程度对目标节点的影响。
GKCI
GKCI, 采用节点分值代替嵌入向量的邻域聚合, 且通过节点中心性灵活地优化聚合分值。此外,结合方向与权重,本文考虑了 4 种情境下的软件网络模型,即无向无权网络、无向加权网络、有向无权网络和有向加权网络。
2 理论基础
2.1 软件网络建模
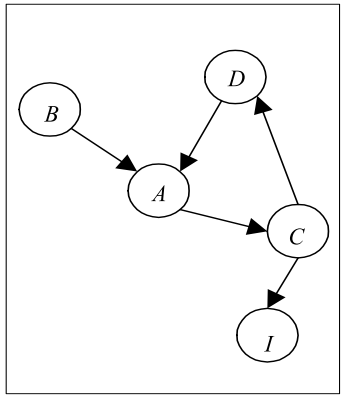
例如,类 B是类 A的子类,根据两者的继承关系,则存在一条由 B 指向 A 的连边(B->A), C->I 代表接口实现关系,C->D 代表参数类型依赖关系, A->C 和 D->A 代表聚合关系。
2.2 图神经网络
GNN 模型对图数据具有强大的表征能力,可同时利用图结构和节点属性信息来学习节点的表征向量,
生成的节点表征向量可用于各种下游任务。
对于给定的网络 G=(V,E),分为拓扑结构信息和节点属性信息两部分,分别用邻接矩阵 A 和节点特征矩阵 X 表示。邻接矩阵 A 是全局共享的, 不会发生变化;而特征矩阵 X 在每层都会更新。
本文对常规的聚合方式进行改进,以实现直接建模节点与其邻居节点之间的重要性关系。此外,借鉴GraphSAGE 方法的思想,本文为每个节点采样固定大小的邻居节点,以降低算法的空间和时间复杂性。
3 研究方法
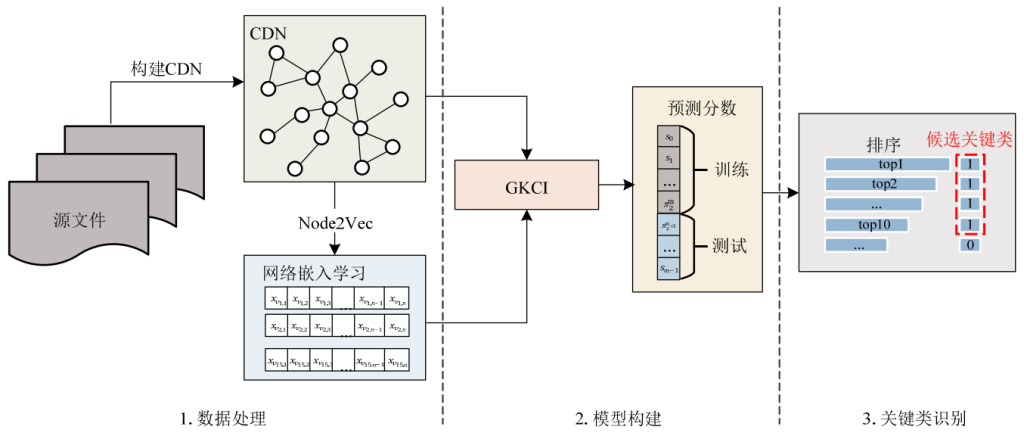
包含 3 个阶段: 数据处理、模型构建和关键类识别。
- 数据处理阶段包括类依赖网络建模和网络嵌入学习;
- 模型构建阶段主要完成 GKCI 模型的训练,包括将学习到的节点表征向量映射为具体得分,并通过聚合层更新分值,以及对节点得分进行预测;
- 关键类识别阶段主要负责将模型输出的节点得分进行排序,评价关键类的识别准确情况。
3.1 数据处理
3.1.1 类依赖网络建模
目标 :将软件系统转化为类依赖网络(CDN),并提取节点表征向量。
CDN=(V,E,W)
- V节点 :软件中的类或接口(如
A.java中的类A),节点 vi表示软件系统中的一个类或接口。 - E边 :类之间的依赖关系(继承、聚合、调用),连边eij表示节点 vi 与节点 vj 之间存在依赖关系。
- 方向 :例如类B继承类A,则边为
B→A。 - W权重 :依赖次数越多,权重越高(公式3),权值 wij 表示eij 边上的权重。
- 方向 :例如类B继承类A,则边为
情境:考虑4种网络类型(无向无权、无向加权、有向无权、有向加权)。
值得一提的是:在加权网络中,边的权重与方向无关, 而与当前的目标节点有关。
3.1.2 网络嵌入学习
工具 :使用Node2Vec 将节点映射为低维向量(保留拓扑结构信息)。
原理 :通过随机游走(结合广度优先和深度优先策略)生成节点的特征向量。
Node2Vec作为节点嵌入学习方法
——探险家的GPS导航
假设你是城市探险家,每次选择下一步时,不仅依赖眼前看到的路标(邻居节点) ,还会用手机上的GPS导航查看:
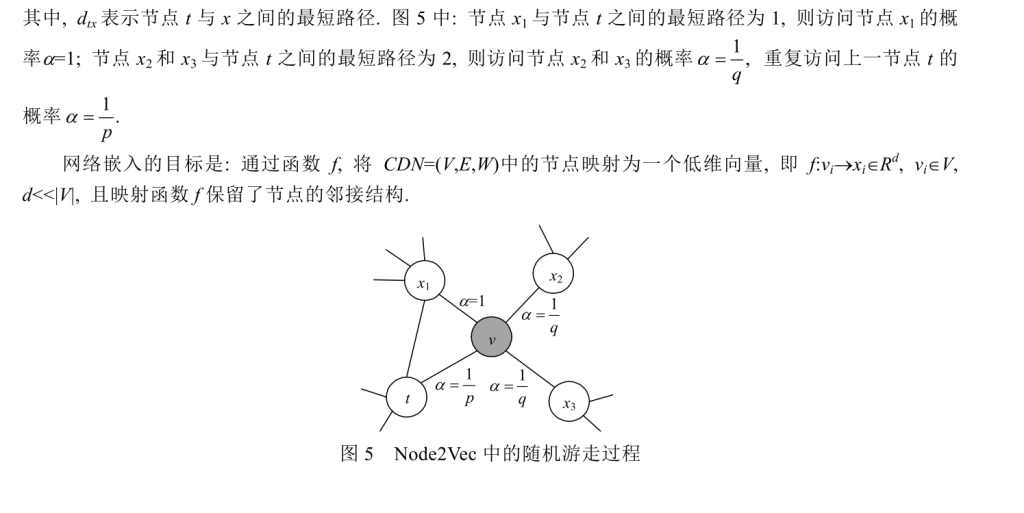
- 从起点(节点t)到目标(节点x)的最短路径长度(dtx)
这个导航信息会直接影响你选择下一步的方向。
参数 p 和 q 的新解释:
- 参数 p(返回概率) :
- 如果你刚从节点A走到节点B,现在想回节点A,GPS会告诉你:
- 如果p值大(比如p=2),回节点A的“代价”更高(比如导航显示拥堵),你会更倾向于不回头。
- 如果p值小(比如p=0.5),回节点A的“代价”更低(比如导航显示畅通),你可能频繁往返。
- 如果你刚从节点A走到节点B,现在想回节点A,GPS会告诉你:
- 参数 q(出入参数) :
- GPS会帮你判断:
- 如果q>1(比如q=2),导航会推荐你探索离起点(节点t)近的区域 (类似广度优先BFS)。
- 如果q<1(比如q=0.5),导航会推荐你探索离起点远的区域 (类似深度优先DFS)。
- GPS会帮你判断:
最短路径如何影响选择?
假设你现在站在节点B,上一站是节点A(即t=A,v=B)。现在要从B出发选下一个节点x(比如x可能是C、D或E):
- GPS计算最短路径dtx :
- dtA(从A到B的路径长度)是1(直接相连)。
- dtC(从A到C的路径长度)是2(A→B→C)。
- dtD(从A到D的路径长度)是3(A→B→C→D)。
- 选择下一个节点的概率α :
- 根据公式(4),α = 1/p(如果dtx=0),α = 1(如果dtx=1),α = 1/q(如果dtx=2)。
- 所以:
- 如果你想去节点C(dtx=2),概率α=1/q。
- 如果你想去节点D(dtx=3),GPS会认为它离起点太远,概率更低(实际算法中会忽略更远的节点)。

3.2 GKCI方法(模型构建)
有点难,没看明白可能明天在更了
Comments NOTHING